The durability property of the ACID model mainly involves how data is safely preserved, such that once a transaction is committed, it will remain so, even if there is an unexpected event like a power loss, crash, or disconnection. Specifically related to FileMaker, there are features including:
- FMS Setting: RAM Reserved for Database Cache
- FMS Statistic: Server Cache Unsaved %
- Database File Recovery
- FMS Scheduled Verify (Consistency Check)
- FMS Scheduled & Progressive Backups (a risk mitigating feature)
Some systems are designed with failure in mind. A great example of this would be a household WiFi router. If a bug warrants a “firmware” upgrade, the process to perform the upgrade is fraught with risk. What if you kick the power-strip while your router is receiving it’s new brain. What if the hair dryer and microwave trip the circuit breaker? Many high risk systems like this include an A firmware and a B firmware. The live system is running on “A”, while your update is going into “B”. Only after the firmware is completely uploaded and verified, is the “primary” switch filled from A to B. In durable database terminology, the switch from A to B corresponds to the commit.

Early bulletproof vest
I like the analogy of this picture to the right… Go ahead, pull the plug on my server… my data is protected. Some systems target data durability as a vital feature. Such features might come with extra overhead, or reduced performance. Being bulletproof is desirable, but might incur some cost and hindered flexibility. This type of database durability is typically built at a low level using a transaction journal. Basically an extra file (with additional disk activity) where the system logs what is about be done and then again once it is done. During recovery, the system can replay the journal to restore the database to a consistent state.
Common Confusion about Durability
The durability property of FileMaker is a topic in which you will find a wide range of opinions, even among FileMaker experts. Just survey experienced developers and consultants with this question, “Is it safe to use a recovered file in production?” Hopefully their answer reminds you to backup often. Hopefully their answer encourages you to explore the various risks and cost associated with this decision.
The low risk position would be found in FileMaker’s documentation. It boils down to: prevent crashes, backup often and, if your server has crashed, the safest move is to restore from a known good backup. There are a handful of additional recommendations given if you find your backups are missing or corrupt. There is not much official information about the severity of risk involved with ignoring this guidance. It does seem clear from their recommendations, that FileMaker does not advertise ACID durability as a design feature of the server product.
General purpose (playing it safe) documentation is not going to help you much when considering your own cost. When faced with a crisis, an experienced database administrator should be ready to consider the business cost for downtime, the cost for data re-entry/recreation, and the cost for data that can’t be recreated. That administrator is the one that is going to ultimately make the decision about the best move during a crisis.
Crash Testing
In an effort to better understand what could go wrong, I performed a battery of don’t try this at home tests, where I intentionally created situations that seemed ripe for corruption and data loss. Understanding the frequency and types of problems that could occur would be helpful both when designing systems and when responding should a crash ever occur. There are two categories of failure that I simulated.
The first type of failure was the loss of network connectivity. I wouldn’t really call this a crash, but I wanted to verify the behavior when the network between the client and server was abruptly severed. Even as technology advances, this problem is actually becoming more common. We’ve gone from hardwired clients that should rarely be interrupted, to WiFi based laptops, to cellular linked mobile devices. What should we expect when a client is abruptly disconnected while in the middle of modifying a hosted database?
The second type of failure should be consider a true crash. In this category, I would include things that might happen to or on the server. This could include this like power failure, SAN failure, OS or process crash, plug-in induced crash, etc. It seemed appropriate to use “kill -9” against the fmserverd process to simulate this type of hard crash. This type of unix signal abruptly terminates a process without allowing any shutdown, closing of databases, or any other cleanup procedures.
Hibernation could be a third type, such as FileMaker Go interrupted by a telephone call, which was not part of this evaluation.
Incremental Append
This test was setup with a single table that had a handful of standard auto-enter fields (primary key, created timestamp, etc.) and a single text field. A client script was then executed which created 10,000 new records, putting a 25KB chunk of lurem ipsum text into the record’s text field. Each new record was committed individually. For auditing, the client script was also configured to save the “last committed record id” into a local text file. A typical run of this script in the testing environment would create about 140-147 records per second, equating to record data throughput about 3.4MB/s. The server was using a SATA SSD, allowing for very low latency and fast random writes.
The test was performed with various server ram cache settings. Swinging between 64MB and 4GB only had a 3% change in throughput, which is probably within my margin of error. At the smaller cache size of 64MB, I would see the server’s cache unsaved statistics climb to 12%(screenshot), which would equate to about 7.7MB of data, or up to about 300 of my records. With a larger configured cache of 4GB, it made sense that the cache unsaved sat at 0%, because the same amount of unsaved data wouldn’t even register 1%.
Multiple times, I caused a hard crash (kill -9)on the server while the script was running. In all but one test, the server logged that a consistency check was required and the file then automatically opened. In these situations, I would examine the last record that the client thought was committed and then the actual record that was saved on the server’s file. In every case, there were some recent records missing. In my tests, these records represented a .1s to .5s lag before records made it to the disk. This is consistent with what one would expect of a server using a write-back cache. See the illustration for what we can conclude about the flow of data after you commit a record.
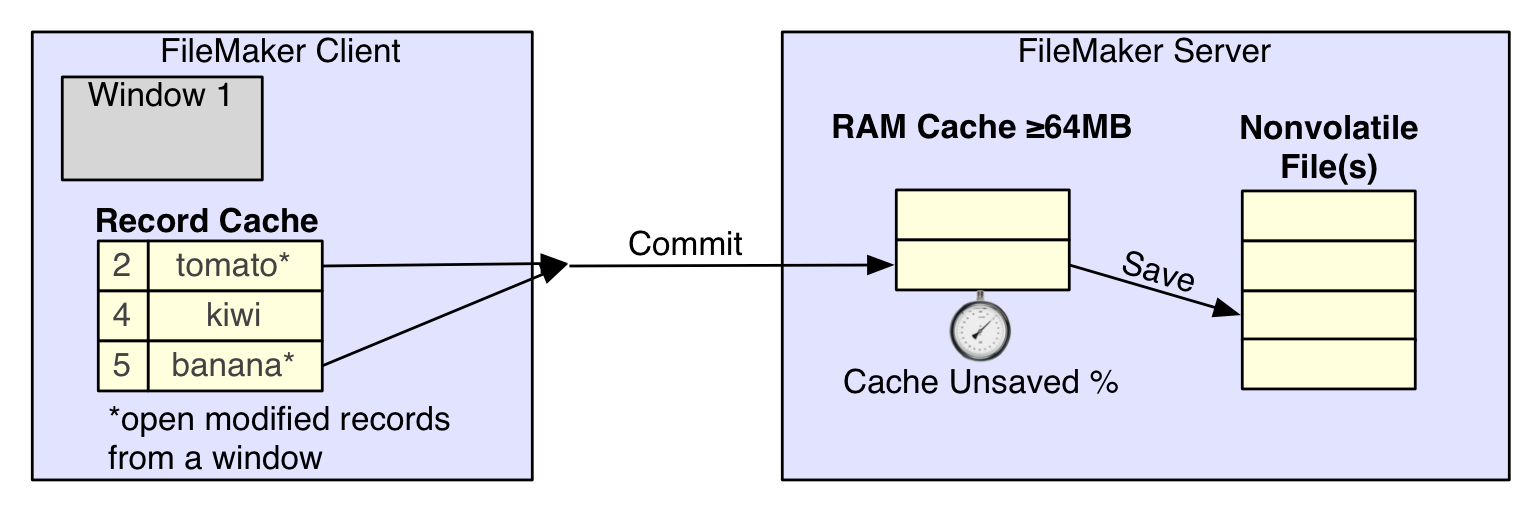
When a client decides to commit changes in a window, the corresponding modified records are uploaded to the server. The server quickly receives those committed changes into it’s RAM cache. Shortly thereafter, the server saves those changes into the database file in the server’s file system. Depending on the rate data is received into the cache, and the frequency and rate with which it is saved to the file, it will create some lag. The amount of unsaved information currently in the cache shows up in a very important FileMaker Server statistic called “cache unsaved %”. The size of the cache does not seem to affect the lag or performance in this test, but it could correspond to the maximum amount of data you risk loosing. In other words, my storage volume was very fast for writing. Even with this very active client, saving was never more than .5 seconds behind. However, if I was using slower rotational media, it is likely I would have seen a larger unwritten data lag. I did not create a testing environment where my cache was ever 100% filled with unsaved data, so I can’t say what would happen in that situation.
Earlier I mentioned that “all but one” on the append tests had the file automatically reopening on the server after a consistency check. There was one instance where the server could not reopen the file. In this situation, I used FileMaker’s Recover File capability. The recover did complete and resulting dialog reported “The recovered file should NOT be used going forward…” with the log indicated 10 invalid data blocks dropped and 5 schema items modified. Close examination of the log revealed those 5 items all related to my high-activity table. As is a common practice, I re-recovered the new file to verify that no lingering corruption could be detected.
Next, I opened the recovered file and went drilling into records near the end of the table, to see what might be found there. Something was very peculiar there(image). As expected, there was a chunk of records that never made it from the cache into the file. But of the last 6 records that were saved, I noticed inconsistent or non-atomic data. Specifically there were 4 records that had all their auto-enter fields populated but they were missing the lorem ipsum chunk from the text field. There was 1 record that was missing 1 auto-enter data element along with the lorem ipsum chunk. There was also 1 record without a primary key, having only a single auto-enter field populated. This illustration may give some clues about what is likely going on here.
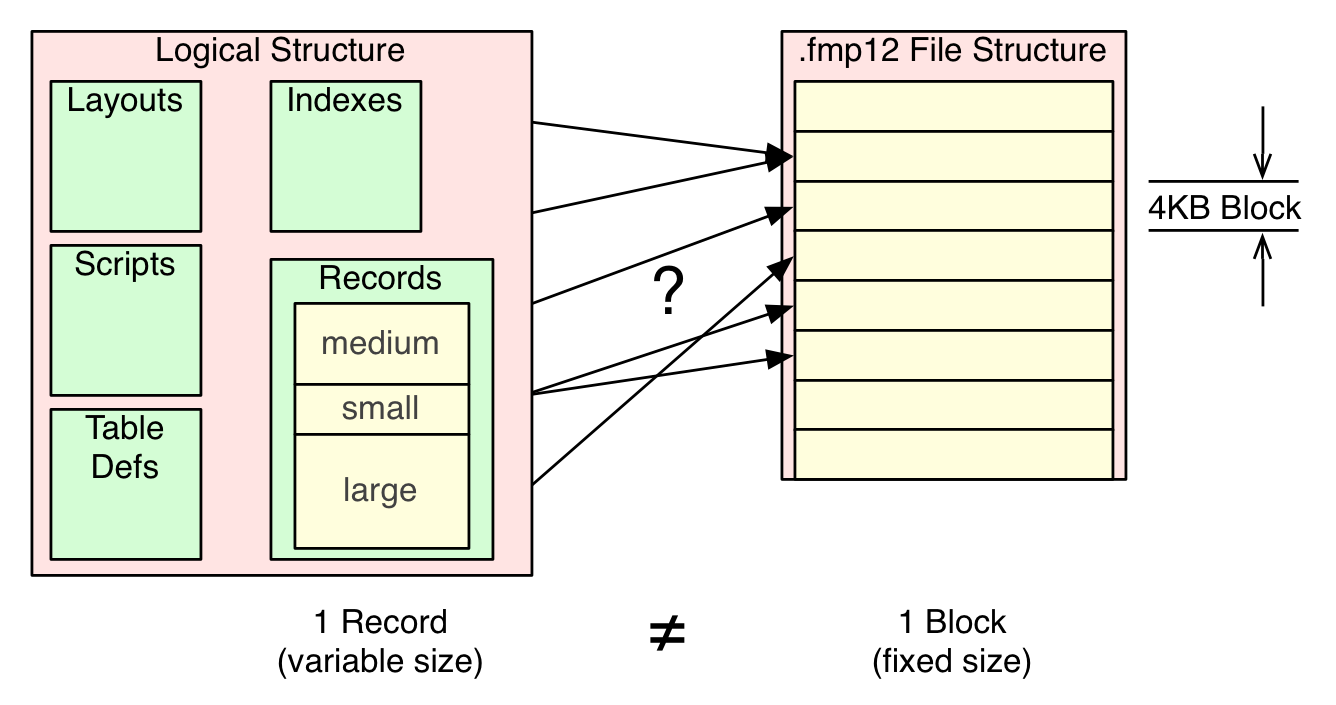
FileMaker’s logical file structure includes solution design elements, code, schema, and record data. Additionally, records in FileMaker are naturally variable in size. Some records in a table may have much more data than other records. Contrast this with the actual fmp12 file format, where information is stored into fixed size 4KB blocks or pages. It is fairly obvious that there is an intelligent mapping needed between logical elements and physical blocks. For starters, my 25KB chunk of lorem ipsum text would require at least 6.25 blocks to store. From this crash testing, it appears that even though the server’s on-line interaction with multiple clients behaves with atomic characteristics, the saving of record data into the file’s blocks doesn’t align directly with a transaction “commit”.
Finally, severing the network while the client was busy creating new records behaved about as well as one could hope. After the client and server both reported the lost connection, I compared the logs on the client with records created on the server. In multiple rounds of tests, the last committed record on the server, matched exactly with the last known record successfully committed and logged on the client.
Atomic Batch Append
Next, I made a slight alteration to the above test. Instead of committing one new record at a time, the script was altered to use a batch transactional method to create 500 new records using a single commit. This process was repeated in a loop to create the 10,000 records. This model does perform slightly slower than the incremental approach, at 115 records per second. This is to be expected considering the bursty nature when 12MB of data is included in each commit. Using the minimum cache setting of 64MB on the server, I did see a couple of times where the cache unsaved percent peaked at 81%.
Hard crashes were again inflicted on the server. This time, repeated testing all resulted in files that could automatically be opened by the server, after a consistency check. As one would hope, the data lost from write cache lag always seemed to align on a 500 record commit boundary. So, even though the corrupted file in the previous test group indicated a non-atomic write of data to the file, it does appear saving is at least “close to atomic” for some situations.
Network connectivity loss was also tested, and again, there was no mismatch between the expected and actual committed records.
Incremental Update
Another test was constructed using 10,000 of the lurem ipsum records, where all of the records were looped over and updated. The loop was performed 4 times for a total of 40,000 record updates. During the test we observe that all 10,000 of the records eventually end up in the client’s record cache. Once the records are cached, almost all of the network traffic is upstream, with the client uploading record modifications to the server. Performance peaked out around 340 records per second or 8.3MB/s. During execution the cache unsaved statistics climbed to 27% of the 64MB configured.
Hard crashes were again inflicted. In four repeated tests, the server was able to reopen the file after a consistency check. Consistent with the previous tests, some data was lost which had still been in the write cache. Comparing the client’s log file to the updated server records, I would see a gap of about 275 records, corresponding to about a .8s lag. This seems proportional to the increased throughput during this test. The server cache was increased from 64MB to 512MB and again there was no perceived change in the amount of lag in the write cycle.
Bank Account Balancing
A more complex test was devised that would utilize multiple tables in an atomic commit. A file was created with two tables to hold balances for checking accounts and savings accounts. The two tables were stored in a single data file. Then 100 customers were generated, each given a checking account with initial balance of $50 and a savings account with initial balance of $50. Each customer’s total worth is $100. After setup, there were 100 records in each of the two tables.
A test module (script) was constructed with the following characteristics: Pick a customer account at random and also pick a transfer amount and direction at random. A transactional process reduces the balance of the customer’s checking account while increasing the balance of their savings account in the second table. Each transfer will be performed with a single-commit transaction to avoid the net loss or gain of money for any specific customer. All operations update existing records and no new records are created. – The test module was then repeated in a loop 10,000 times. After a testing batch, an audit script was then executed to examine every customer to ensure their net worth was still $100.
During stable proving runs, each test batch performed accurately, taking about 40 seconds to run 10,000 transfers, cumulatively 20,000 record modifications per batch. The cache unsaved statistic would hover around 9% of the 64MB configured.
Under crash testing, the server would be terminated about 15 seconds into a batch. For each instance, the server was able to automatically reopen the file after a consistency check. This hard crash simulation was performed 5 times. In the 1st and 5th test, the audit script did find that a customer had gained or lost money. This is troubling information to be sure. This means that, a file “not closed properly” is not only at risk for a lag related data loss, but also that this data loss may be non-atomic.
Conclusion
Is FileMaker durable? NO. This is not an advertised feature of the database engine or file format. Crash testing confirmed that files can become inconsistent and committed changes lost. Mitigating features like backups and recovery utilities should be used judiciously.
These tests eased some of my concerns and at the same time raised some new ones. I expected wider spread corruption than was witnessed. The risk of a file becoming completely unusable due to a crash seems low. It does not appear that anything is working outside the published expectations for the product. Recommendations and cautions previously published are still generally advisable. Developing mobile solutions with risk of network interruption seems well within the ability of an experienced developer who can safeguard valuable data and processes.
There are a few things that we have learned during these worst case scenarios:
- The server’s automatic consistency check is often able to fix/open a file after a crash (>90% during our tests)
- Files without user connections and/or recent activity may not always need a consistency check. This seems to indicate they are at low risk for corruption or data loss.
- File Recovery worked for us, returning a file to an openable state, restoring at least partial record data. This is a useful tool to understand and utilize in disaster recovery. (However, it may not always work. Historical experience has included non-recoverable files, even though they did not appear during these tests.)
- Writing of data from client to server goes first into a cache before it is written to disk. In a high performing server, there seems to be a lag of less then one second before data is safely committed to disk. Adjustment of server cache size does not appear to impact the length of lag.
- It appears that only the very latest changes are at risk for loss. From what we have seen here, risk rapidly diminishes with time after the commit. (>1 second, relative to server performance and other server load)
- In the event of a server crash, there is a chance that atomicity will be violated. Any files that the server reports were not closed properly should be considered suspect. If possible, examine recently added/updated records for accuracy and completeness.
What are some best practices that could mitigate risks associated to durability problems? Many of these are generic recommendations that would apply to any platform.
- Develop a robust backup strategy & backup often. Consider using Progressive Backups. Schedule regular fire drills. Be prepared to restore from a backup, knowing how you will do it and how long it will take.
- Talk with executive management about disaster readiness, considering the appropriate amount to spend on safeguards and acceptable risks.
- Use transactional scripting to protect validity of important business data. This will protect you from network related data loss and also seems to reduce the risk of loss during a server crash.
- Setup a reliable server. Using low quality hardware, outdated software, or untested plug-ins can all increase your chances for a crash. Consider a burn-in or trial period for a server before trusting it with valuable data. Avoid bleeding edge “.0” releases of software unless there are other more important factors.
- Setup a fast server. Using a storage system on your server which is slow during random writes will not only impact performance for your users, but increases your window for data loss in the event of a crash.
- Consider partitioning your data because of size. Larger files take longer to scan for consistency, recover, or restore from a backup. Increasing the number of files may compartmentalize your risk and reduce your time to get back up and running.
- Consider partitioning your data related to update frequency. A file with frequent updates appears to be (naturally) at higher risk for data loss. Isolating data tables into additional files (volatile & unimportant vs. stable & important) may further reduce risk.
- Add logging procedures to your solution. Having information recorded into two or more different tables may help in tracing recent activity or recreating data. Consider storing your log table in it’s own file or even it’s own server.
Caveats
We can’t know what we don’t know. This is true for any system or file format. It is never possible to guarantee that any software or file is undamaged. Verification tools can only ever prove that a file is damaged. If a verification process does not find a problem, it could mean that your file is in good shape, or just that the problem is currently undetectable. FileMaker’s cautious position indicates that they understand how people value their data and that it is impossible to predict what might happen in every situation.
Risks related to live development were not tested for this article. While I am typically a proponent of live development, keep in mind that schema and security changes are ultimately another object that the server needs to write into that file. Reports have circulated where files have been damaged in the “users & privileges” area. If this occurs, FileMaker’s security safeguards might prevent you from recovering a file. Clearly schema changes and a server crash would be a dangerous mix. Tread carefully in this area.
Testing Configuration
All of the durability tests were performed on a GigE LAN, with a FMS 14.0.2.226 on OS X 10.10.5 having 10GB of RAM, having both OS and databases stored on a SATA attached SSD. Client machine was using FMPA 14.0.5 on OS X 10.10.5. In-between transactions, some tests used the BaseElements 3.1 plug-in on the client for writing a local log file.
About the Author
Chris Irvine is a Senior Technology Consultant at Threeprong.com LLC, and a certified FileMaker Developer. He develops on multiple platforms, specializing in custom workgroup solutions, B2B integration, and performance tuning. Contact Threeprong for your next custom solution or for help taking your existing solution to the next level.
Related Articles
0 Comments
Leave a reply
You must be logged in to post a comment.