Introduction
Serialization is a common technique used to enclose multiple items or complex data structures into a simplified stream of information. That stream can be stored or transported and then later retrieved. The most common place we see serialization used in FileMaker, is for passing multiple script parameters. As the medium for transporting information between scripts is limited, developers serialize their data and then later reconstruct it. There are certainly other opportunities to use serialization in FileMaker, maybe you haven’t considered them all:
- Script Parameters – pass multiple parameters or complex data structures when calling a script
- Script Results – pass error information, messages, or complex data back up the script stack
- Perform Script on Server – pass and return information between client and server for a split script stack; leverage lower latency, higher bandwidth, and potentially a faster CPU
- Web Services – serialize data to exchange with web services that you consume or produce
- Database Blobs – rather than structuring data into many fields, it might be appropriate to store structured data into a single field
- Deferred Parameters & Results – store script parameters in a work queue record, such that an asynchronous scripts can be performed by a server schedule or robot
This article attempts to be a fair comparison of several popular serialization techniques. If you don’t already use serialization, it is an important concept to master. I think you will quickly find it to be an essential building block for any significant development project. If you already use serialization, it might point out performance or security gotchas that you can better handle in the future. Options that might require a plug-in could provide significant advantages, but wouldn’t be portable to FileMaker Go, so they are not part of this comparison.
Information will be presented here for each of 3 comparative tests. Then I’ll comment on the strengths and weaknesses of each technique.
Features
| Value List | Six Fried Rice | Property List | FM Standards | JSON | |
|---|---|---|---|---|---|
| Approach | Value List | Dictionary | Dictionary | Let Notation | Dictionary |
| Nesting | No | Yes | Yes | Yes | Yes |
| Evaluate() Risk | No | No | No | Yes | No |
| Flexible Keys | N/A | Yes | Yes | Limited | Yes |
| Flexible Data | No | Yes | Yes | Yes | Yes |
| Readable | Unlabeled | Fair | Good | Fair | Good |
| Density | Good | Fair | Good | Fair | Good |
This feature comparison shows important differences between different techniques. Depending on your use case, some factors may be more or less important to you. The readability and density notes are a little subjective, but sooner or later you may need to debug code and/or deal with nested escaped data.
Note: There is some confusion, at least for me, around the term “value list.” To many, this term is associated with the FileMaker feature related to data displayed in various selectors which may be manually defined or derived from indexed database fields. However, it may also be used to refer to the text generated by List() and later accessed via GetValue(). There are plenty of places these two concepts overlap, such as the ValueListItems() function. All of references in this article are referring to the later, which is simply a chunk of text where “items” or “values” are delimited by carriage returns.
Test Environment
Desktop tests were performed on a Macmini6,1, 2.5GHz i5, 10GB RAM, running OS X 10.10.5 and FileMaker Advanced 14.0.2. Desktop testing was performed with files stored locally on internal SSD storage and a cold application launch before each test.
Mobile tests were performed on an iPhone 6, 1.4GHz A8, 1GB RAM, running iOS 8.4 and FileMaker Go 14.0.3. Mobile test files were transferred to and from local phone storage using iTunes. Every test was performed after the app was discarded from switcher and then started cold. Power was attached and device was not allowed to sleep.
Test One – Basic Parameter Performance
Developers are tasked with a specific problem or feature, and we dive in, coding a solution. Before long, you might start to realize this thing is getting a little bigger than you would like. One asks, “I wonder if I could break up components of the solution into sub-scripts? That would make development and maintenance easier, but will I face a significant runtime setback? What about situations where I need to pass state information to those sub-scripts? Is there a limit to how much information I can relay between scripts before there are significant performance impacts?” This test was structured to help answer those questions.
The most common use case for serialization is to pass script parameters. The assumption here is that you need to pass multiple pieces of data to a sub-script. That data might be simple elements like numbers or dates, or include richer data like paragraphs of text supplied by a user input form.
About The Test
The test works first from a calling script, incrementally collecting data into a serialized string. The data elements are a variety of types including numbers, string snips, list-of-values, dates, times, and timestamps. In the first round, five elements are serialized in single dimension. Then a sub-script is called and all the elements are decoded back into variables with their appropriate types. In this model, we total all time spent by the calling script, the passing of the data, and the decoding in a sub-script. The test round repeats the test multiple times of ensure consistent performance. Later rounds each doubled the number of serialized elements.
The positional parameter approach is included in this test, but with limitations. Value lists (aka. list of values) were escaped with a simple line break substitution. This works with well formed data, but rigorous or risky escaping functions would be required to support free form data like all the other techniques support. Additionally, the positional approach has data which is not self-documenting, so developers must maintain their own documentation on all elements and the required order, where as other techniques support named out-of-order elements.
Property Lists were tested two different ways. In a manual approach, the developer decides which elements require full escaping and does some of the simple key-value concatenation. In the convenient approach, a custom function is called to uniformly assemble every element with built-in escaping.
FM Standards’ recommended functions utilize FileMaker’s Evaluate() when processing data. As such, any untrusted origins of serialized data can put your solution at risk. Since these tests are within a trusted script call environment, we don’t perform additional operations that might otherwise be necessary. The FM Standards technique is tested three different ways. The fastest and most convenient technique automatically assigns every passed element into a variable. The second approach, uses a filter to limit assigned variables to only items desired by the client. The third approach is similar to other dictionary techniques, where elements are retrieved manually as needed.
This test is run with a macro mindset, comparing the pace at which you could likely process information with repeated script calls. Some readers might prefer to see the bias or baseline performance subtracted from the results. We didn’t do that here, but efforts were made to perform similar work during setup and processing between each of the techniques. Raw data is available for anyone that would like to dig deeper.
Results
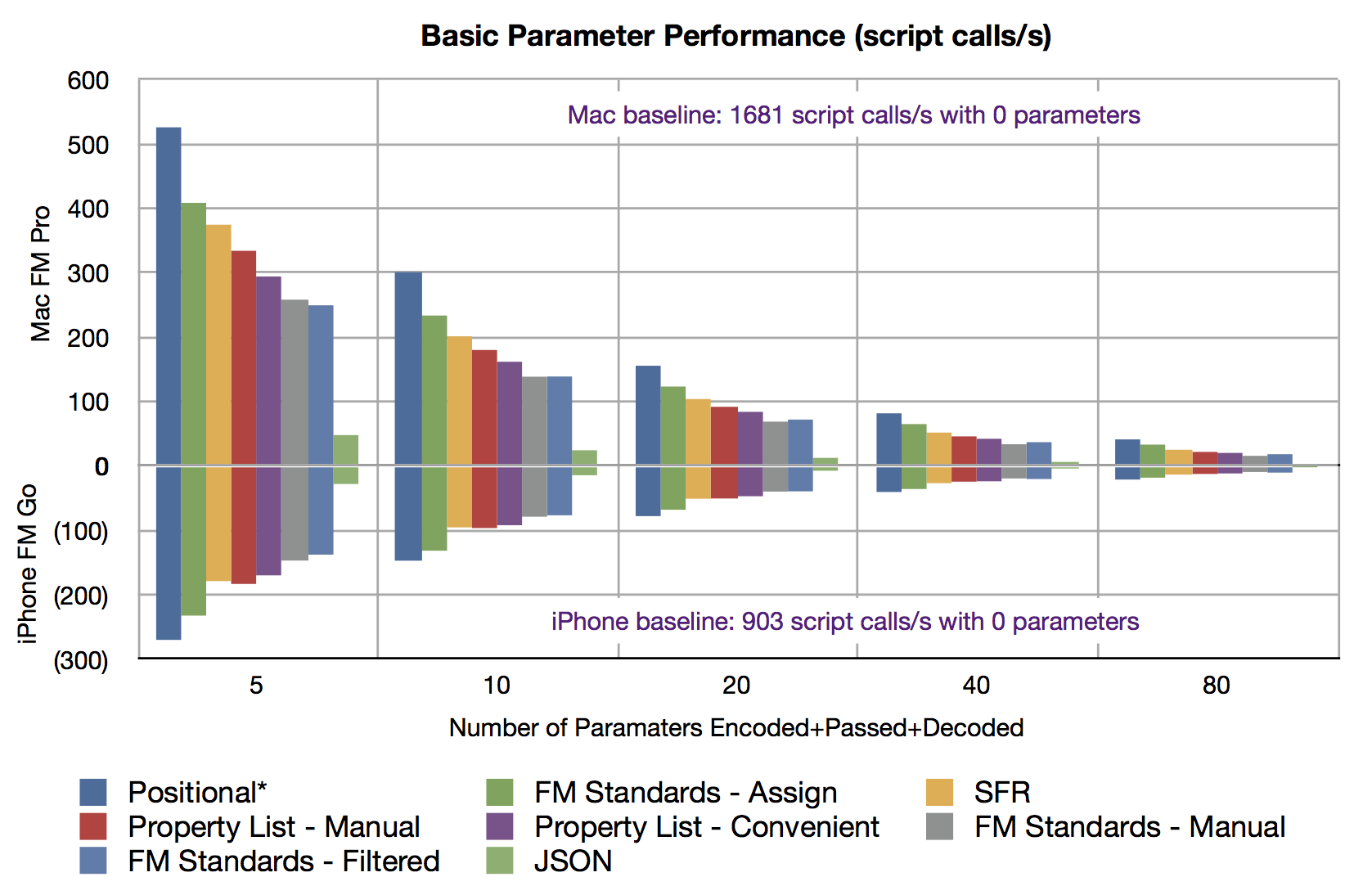
The results show the number of times the main script encoding together with the sub-script decoding can be performed per second. As expected, the simple nature of positional technique makes it the fastest but not nearly as much a previously thought. FM Standards, with the bulk assignment via Evaluate(), performs consistently fast. Comparing the results as more elements are passed, seems very uniform with only minor variance.
iPhone tests showed very impressive speed. These tests, which do not touch database records, ran about half the speed when compared to the same test on a desktop. It also is encouraging that a phone, with limited resources, seems to exhibit a similar scaling characteristic.
Encoded Data Samples: Encoding Samples Five Parameters.pdf
Take away: Any speed argument for not using Name-Value-Pairs for your parameters seem moot unless you have very special case. Hundreds of calls per second is sufficient for most applications. As expected, the performance gradually decreases with additional parameters. You probably won’t have a problem unless you combine many parameters with a high number of script calls. With the possible exception of JSON, these techniques would perform sufficiently well for consistent use in both desktop and mobile.
Test Two – API-like Structured Data
As systems increase in complexity, they will likely need to interact with external web services. Developers might even adopt a web-services model between internal systems or even areas of a FileMaker solution. One common external service a client might interface with could be a payment processing vendor. This test is patterned after the type of structured data that might be passed to or from such a vendor.
About The Test
This test was setup to look at both the time to encode and also decode information. In the web services model, there is often much more data passed than actually required. As such we use manual methods to retrieve each element by name. Another common paradigm is object style structures, where groups of elements are nested inside each other.
The structured data was setup as a tree with leaves containing data. For this test, I configured 5 branches at each level and leaves 3 layers deep. The resulting structure contains 5³ or 125 leaves. As in the first test, a variety of data types are encoded and decoded.
Positional parameters don’t apply and are not included in this test. Property List was encoded using it’s convinces functions. FM Standards was decoded with manual element retrieval.
Results
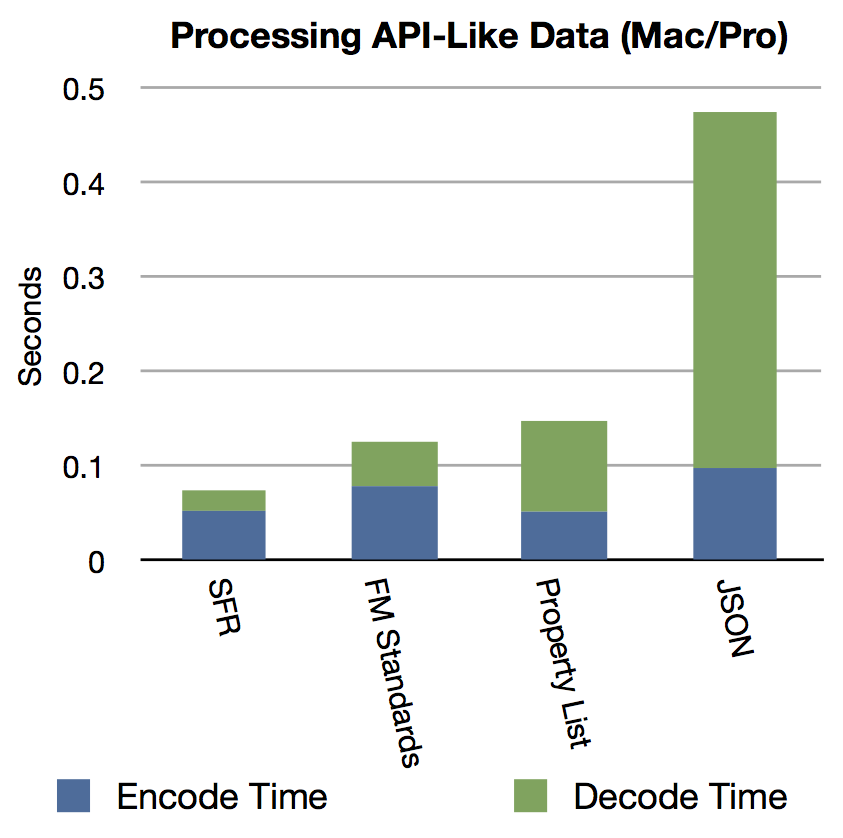
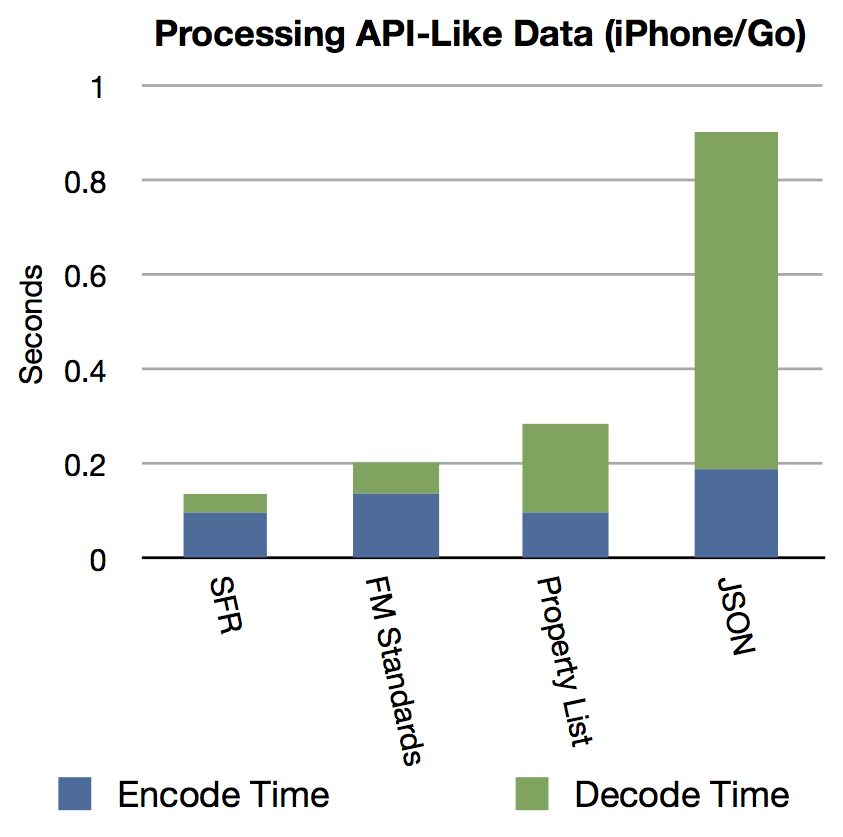
The Property List and Six Fried Rice technique were a tie for the amount of time it takes to encode a data structure. Six Fried Rice’s technique was the fastest during decode. It is interesting that the design paradigm of FM Standards is slower during the encode stage where as Property List is slower during the decode stage. Uses cases that that more frequently encode, or vice versa, might want to consider these results closely. All three of these methods can encode and then decode a 5³ tree in under .15 seconds. JSON content is widely used by public facing APIs and web services. Retrieving every element of a 5³ JSON tree can be performed in .4 seconds. However, utilizing JSON for internal application communication could cause slowdowns.
The iPhone performance is again very impressive with the timing results that almost mirror the desktop, with the scale indicating they take about twice as long.
Encoded Data Samples: Encoding Samples API-like Data.pdf
Take away: Using structured objects for inter-application communication performs very well and can be adopted even for routine parameter passing. Care should be used if you are regularly encoding or decoding complex structures in a tight loop. The current JSON functions are reasonably fast for occasional use, like communication with an external vendor, but not yet fast enough for routine parameter passing.
Test Three – Larger 2D Data
Sometimes it make sense to isolate chunks of code that are used for import, export, or report generation. If you can separate business processing from presentation, you will find that much more of your code is reusable and easier to enhance. The concept behind this test was based on a real world case where we found a developer importing a large report from an external vendor, and then handing that data through a script parameter to various routing and processing scripts. Having good performance applies in multiple areas: technical limits, speed, memory efficiency, etc.
About The Test
This test was designed around a spreadsheet type example. For the desktop test, the spreadsheet was designed with 50 columns, 2000 rows, and 27 characters per cell, resulting in 2.57MB of cell data. Since the iPhone has less RAM and a slower processor, it’s spreadsheet was designed with 20 columns, 1000 rows, and 27 characters per cell, resulting in 1.29MB of cell data. Since JSON supports both objects (named elements) and arrays (organized by position, retrieved by index number) it seemed that it would be interesting to compare both approaches. Unlike previous tests, the same type of text data was used for every cell.
The first stage of the test measures encoding performance, assembling the entire spreadsheet in a pair of nested loops.
The second stage of the test attempts to decode the spreadsheet from top to bottom. The decode approach process first decodes a row out of the sheet, then a cell out of the row. Because the decode process is significantly slower than the encoding I only decoded the first 100 rows from the sheet (50 rows on iPhone).
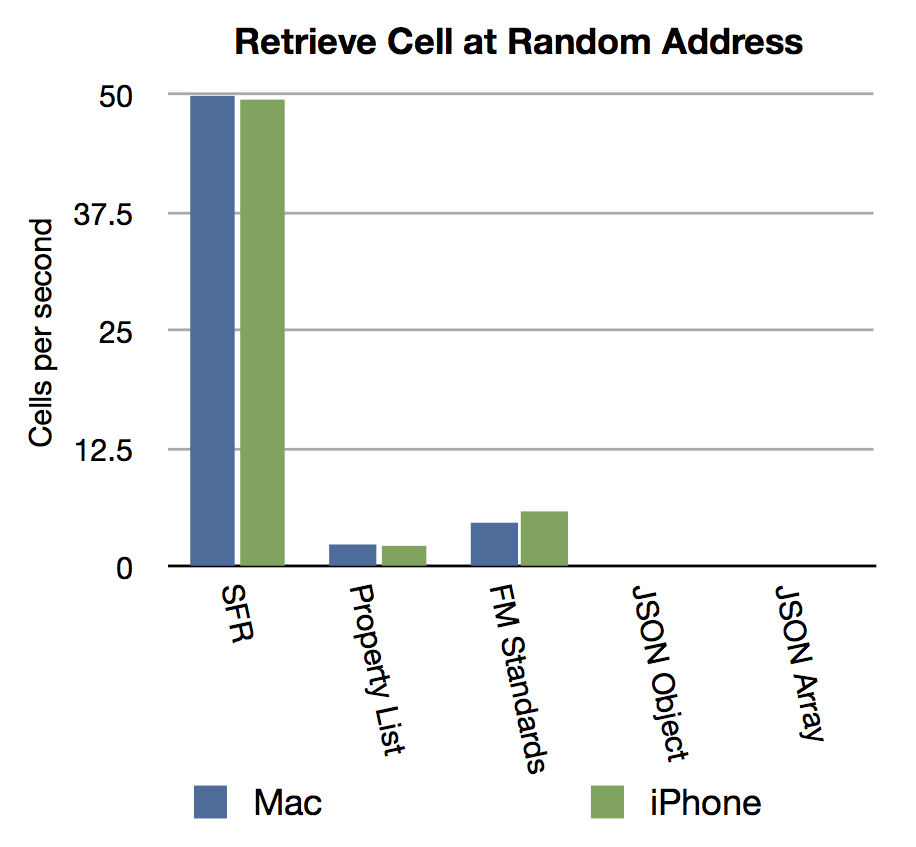
The third stage of the test attempts to read 50 random cells from the sheet, again first the random row, then the random cell. Every cell address was chosen at random. For this stage on iPhone, we also did 50 random reads.
Results
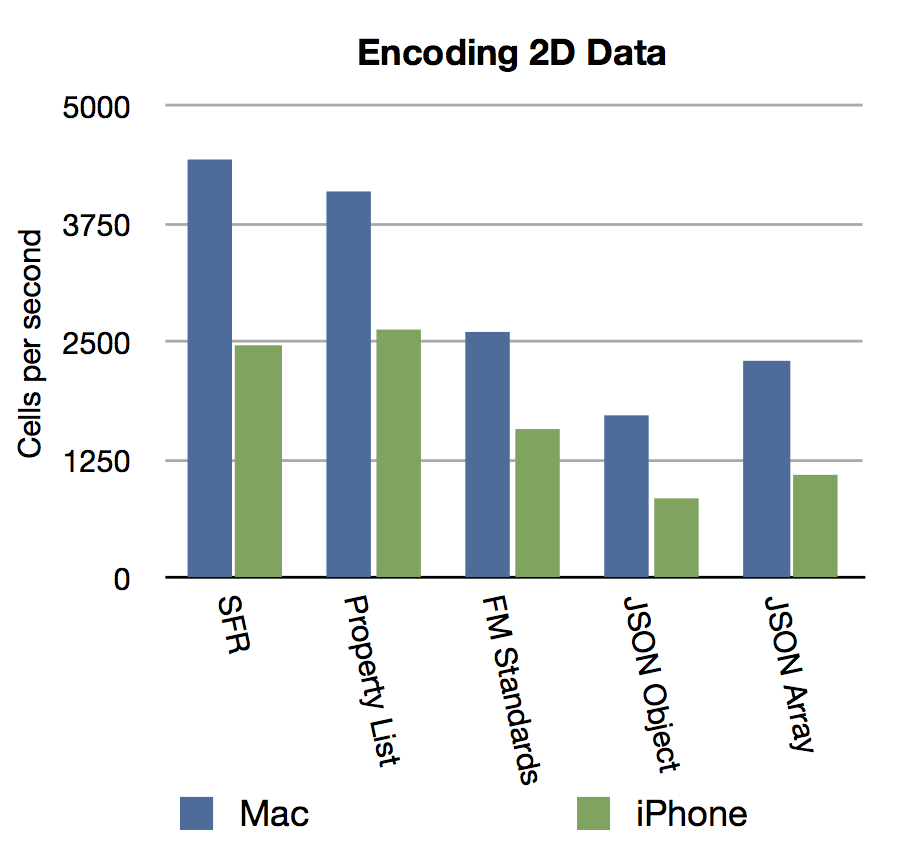
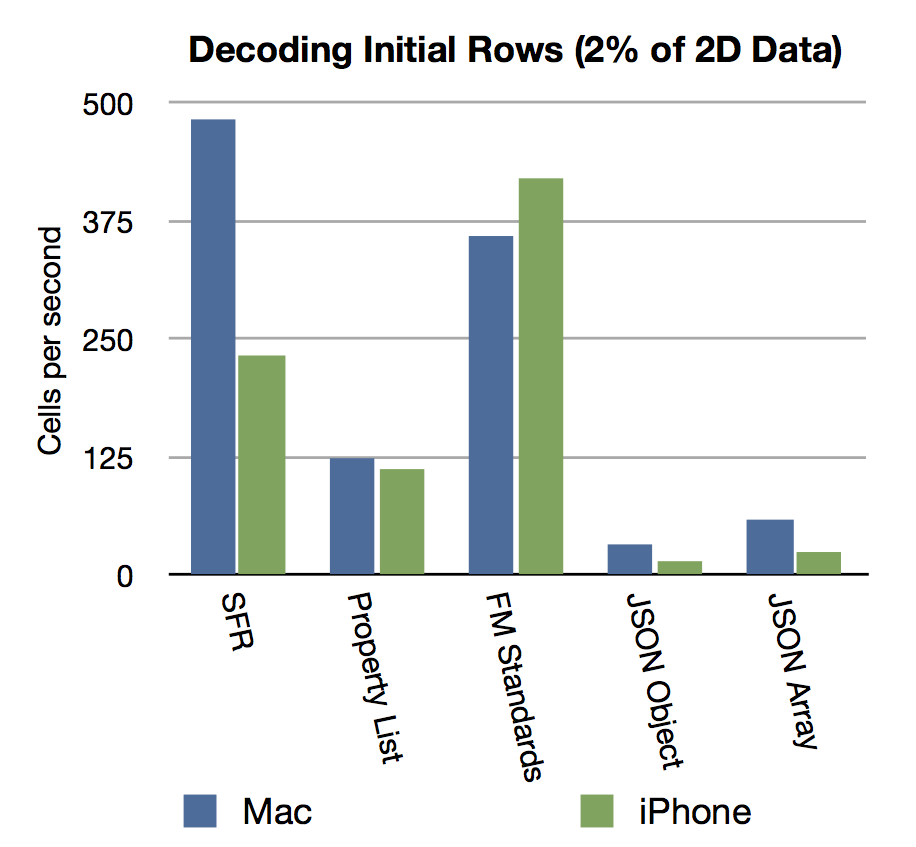
During the encoding stage, most techniques seemed to perform reasonably well, combining well over 1000 cells per second, even on the iPhone.
During the top to bottom decoding stage, there appear to be some clear advantages to the Six Fried Rice and FM Standards techniques. There are concerns about how the performance might degrade as the number of the row retrieved increases, since some of functions have to seek past data to reach later sections.
During the random access stage, the Six Fried Rice technique is a clear winner, performing an order of magnitude better than Property List or FM Standards. The JSON technique really struggled here, many of the tests did not finish in the time allowed.
Encoded Data Samples: Encoding Samples Spreadsheet.pdf
Take away: Working with more than 1 MB of two dimensional data is certainly possible using techniques from Six Fried Rice, Property List, and FM Standards. However, you may spend a serious amount of time traversing these large amount of data, even though it may exist purely in memory. In situations where you need to import or hand around large chunks of data, it may be worth your time to consider utilizing a temporary or slush table where records and fields are used to store the 2D data. It also seems clear that JSON isn’t currently the right tool for random access of large tabular data in FileMaker.
Storage Efficiency
Now is a good time to compare the markup overhead of the various techniques. When cell data of test three, 2.57MB, is encoded with various techniques, the total size of the serialized string varies significantly. Both JSON Array and Property List are significantly leaner than the other approaches. This difference is tied to design decisions about markup syntax and escaping.
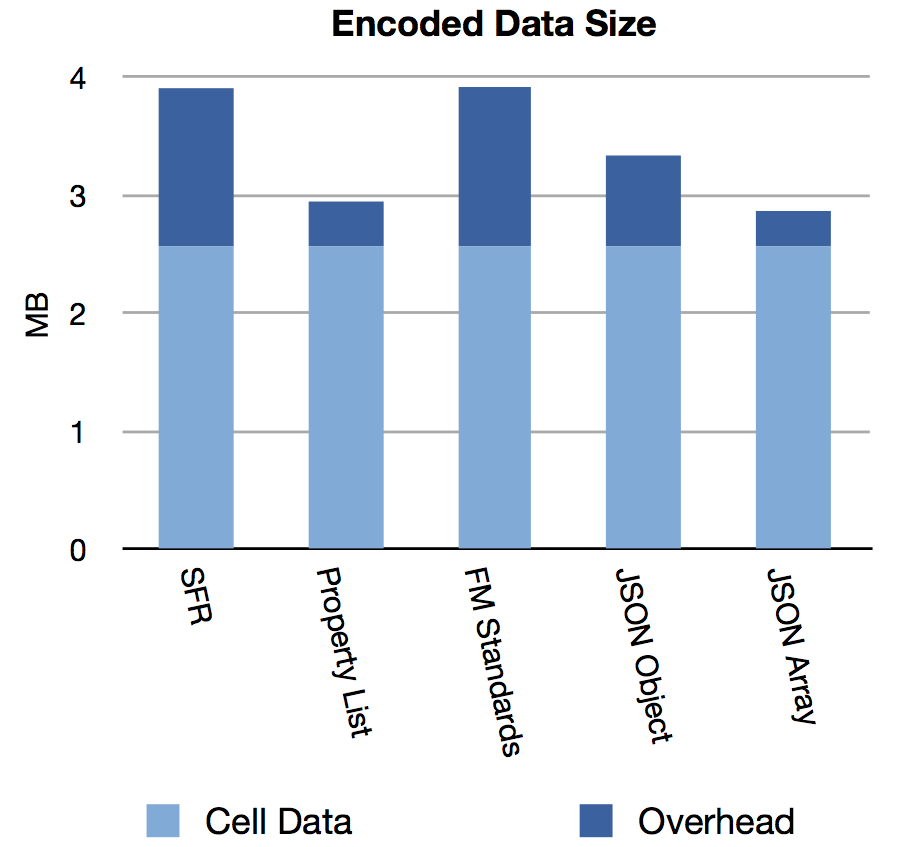
Take away: As many of us are starting to use Perform Script on Server to optimize user experience for WAN clients and slower devices, the size of the script parameter could be a significant factor. Using a technique which has unnecessary overhead might mean slower responses if that client is on a slow link, such as legacy cellular data.
Summary of Each Serialization Technique
Positional Values
Using a traditional list of values for serialization is possible and favored by some. While there is limited functionality, the performance can be quite good. However, the performance isn’t necessarily that much better than using Name Value Pairs.
The main drawback of positional values are the technical limitations. More over, best practices with advanced scripting lean away from this technique, with a preference for clean documentation, optional parameters, and easy refactoring. It might be most appropriate to use positional values exclusively in situations where performance tuning shows a benefit.
Six Fried Rice Dictionary
The functions from SFR performed in the front of the pack in almost every speed comparison. In some cases the lead was very small, and in a couple situations, the lead was more significant. From the performance perspective, this technique is an excellent option.
The significant drawback we see with the SFR technique is the markup, which is admittedly, a little subjective. The syntax and format appears to be custom, and doesn’t bear many similarities to JSON or traditional FileMaker data structures. Looking at raw serialized data while debugging isn’t too bad until you start nesting and your screen gets clogged with the heavy handed escaping. This can also result in a rather plump payload if you are using a slow network.
Property List
The Property List functions performed quite well in most situations. One areas of strength is it’s readability in a debugger and light weight escaping which keeps it lean and relatively readable even with nested elements. The strong ties to FileMaker’s own list-of-values format may help with accessibility for new developers.
The significant drawback I see with Property List would be some potential slowdowns if you are dealing with several hundred elements.
FileMakerStandards.org Let Notation
The FM Standards functions are extremely convenient. Great effort had been taken to detect and preserve data types. Rapid development, popular in FileMaker circles, often prefers the ‘Assign’ approach of expanding all parameters as variables in a single step. This approach can work well with a reasonable number of elements, but is less applicable to serialized data in database blobs. The documentation and community support behind these functions is another strong benefit.
There are a few drawbacks with Let Notation. The one major issue is security. Malicious injection to serialized data is a real risk. Code that utilizes Evaluate() is generally contrary to defensive programming, if you appreciate that sort of thing. If you are a script receiving parameters from an untrusted caller, there is no convenient way to protect against injection. Other issues are the overhead with the markup and also some limitations on the allowed keys inherited from variable naming restrictions. Regular use of the ‘Assign’ approach may result in poorly documented code.
JSON Custom Functions
The JSON custom functions are a fantastic addition to the community. The biggest reason to consider using JSON is it’s wide spread adoption in the rest of the software development world. It is excellent that you can directly communicate with public web services without any plug-in and even from a standalone mobile solution.
The biggest drawback with the JSON technique is performance. Since the JSON markup comes from JavaScript, there isn’t much in common with traditional FileMaker data formats and tools. The effort to assemble and parse JSON with current functions is a chore and it shows with the comparatively slower performance. These functions are relatively new, so there is a possibility that optimizations could be made.
Once encoded, JSON is clean, lean, and highly interoperable. We can only hope that FileMaker starts providing native JSON functions as part of the platform in future versions. I think there are many of us that would quickly migrate to JSON for parameter passing if native functions become available.
Resources
Links & Downloads
- Six Fried Rice Dictionary Functions
- Property List (hosted here)
- FM Standards Parameter Passing
- JSON Custom Functions
- Testing Package Download – See raw data or test your own techniques
Author’s Notes
Chris Irvine (that’s me) is a Senior Technology Consultant at Threeprong.com LLC. I contributed significant portions of the Property List techniques that was one of the packages profiled here. Much of the work on Property List was done with the help of a skilled team of people working at Dr. Bott, 2007 through 2014. Testing and writing about the competition is mostly for my own benefit. Many capabilities and performance revisions to the Property List functions came out of comparative testing like this. I hope that these resources are beneficial to other developers, spark lively debate, and help us to further the state-of-the-art.
Some feedback for this article included suggestions on optimizations that are available with, or to improve the performance of specific techniques. One way to approach the above performance comparison, would be to present a challenge and then allow developers to make the fastest possible solution within one of the above techniques. I’m quite sure that the resulting algorithms would have significant differences and scaling behavior. For today’s topic, we’re hoping to help with the selection of tools that work well with ordinary tasks. The approach here was to use typical solution patterns and then interchange serialization techniques with only the minimal necessary code changes. Specialized and optimal approaches for working with big data would be a great topic for another post.