
That portal looks right, but I’d really like to see the newest information at the top. Can you change that?
Well, yes, I can do that… But things could grow slow if there is a lot of related information.
How many times do your customers ask for a portal showing sales or purchasing history of a product? Or maybe an invoice history for a customer. In most of these situations, they want the portal sorted newest to oldest. If there will only be a few dozen related records, then the fix is simple, just configure the portal to sort descending based on a field like Creation Timestamp or Serial ID. However, when there are hundreds or even thousands of related records this can become very problematic and a real performance dog. The same can be true of list views, or even sorted relationships. Sorting is certainly always a red flag when it comes to performance as the data set grows. This is even more pertinent with a WAN-first methodology.
There are many smart ways to work inside these types of limitations. I specifically like the Tom Fitch method described in, FileMaker Portal Sorting That Doesn’t Suck™. I would also like to see this behavior as a native feature in FileMaker, as proposed in, Reverse presentation order, for portals and layouts. After writing most of this article, I found a similar sorting concept described by Daniel Wood, but his strategy is different, actually avoiding the sort. I think the following implementation is simpler and more flexible.
In the recent years, I learned from several of my esteemed colleagues about using an Unstored Calculation defined as Get (FoundCount) as a fast counting technique for related records without actually fetching the records. This has turned out to be a big performance help as I support more and more clients which are connected to their database remotely. Having known for a long time that the slow part of sorting is typically downloading all the records from the server to the client, it got me thinking if I could come up with a way to sort records without downloading them.
Hello 10x Sort Speed!
After much testing and benchmarking, I now wholeheartedly recommend using Get (RecordID), in an unstored calculated field, as the method to support what I describe as reverse natural order. You can now throw caution to the wind when it comes to revealing a large number of records in a sorted list or portal.
Test Results
In the search for the ideal sort strategy, I selected a large-ish table from one of my customers. It’s a mature system and the selected table contains 82,000 records with various fields types. (Mature is a nice way of hinting about legacy patterns and bloat.) A local front-end file was configured with a reference to this hosted table. Then a few test scripts were setup to measure the amount of time in two stages: first to “find all” records in a list or portal, and second to measure the time it takes to sort the records in reverse. The goal such that the newest record is revealed at the top of the list/portal. Between each test, I quit FileMaker and removed all caches to consistently simulate a “cold start”.
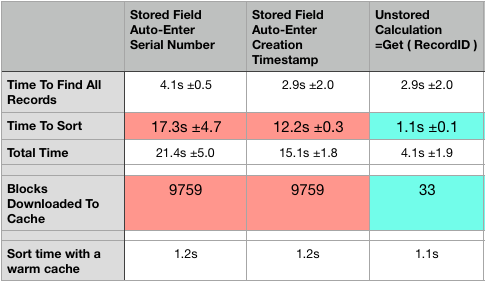
Notice that the sort time on any of the stored fields takes well over 10 seconds and the sort time on the unstored field takes only about a second. This is opposite of what we typically expect. Here an unstored field performs faster than a stored field.
Setup – Easy as Pie
Step 1 – Create a field for RecordID. This IS NOT your primary key.
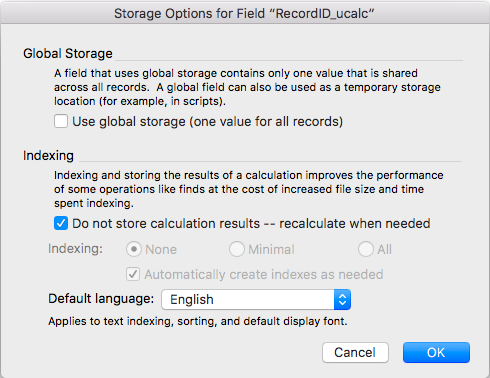
Step 2 – Be sure to check “Do not store calculation results”. This is essential. Without it, the field will be stored and trigger the slow download of all record data.

Step 3 – If using a portal, you need a relationship from an anchor table to another. Nothing fancy here.
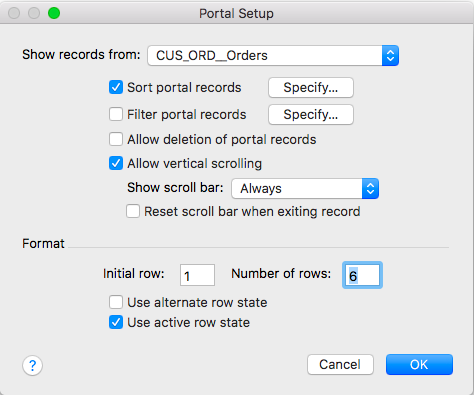
Step 4 – Create a new portal and drill into “Sort portal records”
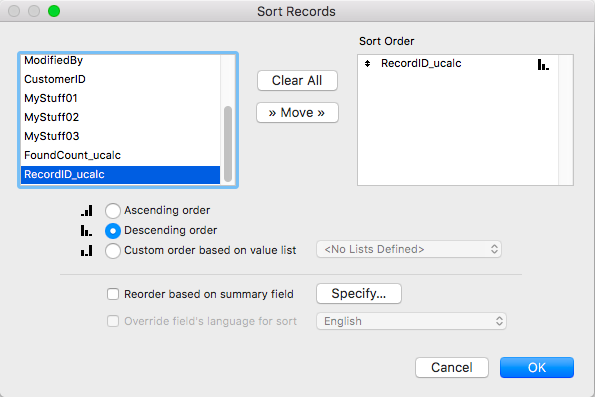
Step 5 – Use the RecordID field with descending option to display the records in reverse natural order.
How can this be? Looking Under the Hood
The stored record data for this table is about 39MB (not counting container fields). This number is important because the smallest unit of data that FileMaker fetches from a record is the whole record (less unstored fields and calculations). This file also has a bunch of index and container data. This turns out to be irrelevant because FileMaker doesn’t currently use indexes in the sorting process. Also, container data is fetched just-in-time, only when the container is revealed on a layout or required by some other calculation.
In a traditional sort, when based on any stored field, FileMaker will present a “Sorting…” progress bar as it fetches all 82,000 records from the found set. As often as I proclaim that latency is the most important factor for WAN performance, in this situation, bandwidth is the bottleneck. For this particular environment, the transfer of data from the server to the client is limited by a 25Mbit upstream cap. By simply running the numbers, it will take about 12 seconds for the client to download all record data. Add some congestion and this time will climb. Traditional solutions have been: reduce the number of matching records, try to make the records smaller by deleting fields, or simply do not sort.

This trick is to avoid downloading the records in the first place. There is a stage before records are downloaded, where FileMaker downloads metadata about the records. If you think about the the record navigator in the top left of your window, there is information about the number of found records, the current record, etc. This is why using an unstored calculation for Get ( FoundCount ) is so crafty. It utilizes this metadata without actually reading record data. The same turns out to be true for an unstored calculation with Get ( RecordID ). It appears that FileMaker’s internal ID for a record is retrieved as meta-data. We can use this quasi-field as the condition for our sort with incredibly great speed. Only after the sort is finished, does the engine fetch some record data. Based on my test results, it is only going to fetch a handful of records as required to display on screen and if a list view, a few records for the next screen.
What about Caching?
To be fair in advertising, the speed improvement claim I am making has to do with cold starts. This applies the first time a user is fetching a set of records. After that, FileMaker uses a persistent record cache which lives through quitting and launching the app. This does mitigate the download penalty when you revisit records. However, there still does appear to be some additional sort cost when using real record data, even if from the cache, when compared to only using record metadata.
Unstored Calculations are The New Hotness
After years of avoiding unstored calculations, I’m starting to have a new fondness for them. I’m looking for other places where I can skip fetching a record, using only record metadata. Ok, ok… just because you can, maybe it’s still not great UX to show 100,000 related records in a portal. But, my comfort level is now much higher and I will probably use various hybrid approaches that first reduce the number of records, and then combine this technique as a pain free way to sort the remaining records.
Choosing to make a calculation unstored will also make the record narrower, because they don’t materialize until you need them. So long as you know that finding on an unstored field is a very bad idea, there might be sensible times to opt-out of storing calculation data, deferring the work until needed.
Caveat #1 – Maybe you want the portal to load slowly… It’s not always terrible if FileMaker is fetching many records in order to sort by a stored field. In the right circumstances you may receive this peaceful progress indicator. The advantage here is that you pre-fetch all the records used in the portal into the cache. Later on, the user should experience smooth scrolling in the portal. If you deferred loading all the related records, then records will load just-in-time. This is most noticeable if you grab the scroll bar and try to go to the middle of the list which was not previously fetched, but scrolling gradually with the mouse-wheel-style seems fine.
In case you are wondering, my first implementations of this technique actually used Get ( RecordNumber ) which does seem to work equally well, but just feels a little more obscure and hard to explain. Using the Get ( RecordID ) function seems like the better choice.
I’ve been using these techniques in production for a while without any regrets, but I’m sure there are caveats that I haven’t encountered yet. No warranties. I look forward to your feedback and comments.

Related Articles
1 Comment
Leave a reply
You must be logged in to post a comment.